
















明明是表格PDF,pdf转换成excel后却变成乱码、错列、空白一大片:金额跑到备注列,合并单元格全散架,最后还得手动重做一遍。先说反常识结论:不是所有PDF都能一键完美转Excel,关键在于先分清它是“可编辑的文本型PDF”,还是“图片扫描版PDF”。
本文按真实办公场景,手把手讲清:pdf怎么转换成excel、不同文件怎么选方法、免费方案能做到什么程度,以及转完常见翻车点怎么修。照着做,成功率会比盲目上传高很多。
先判断PDF类型:选对方法,成功率直接翻倍
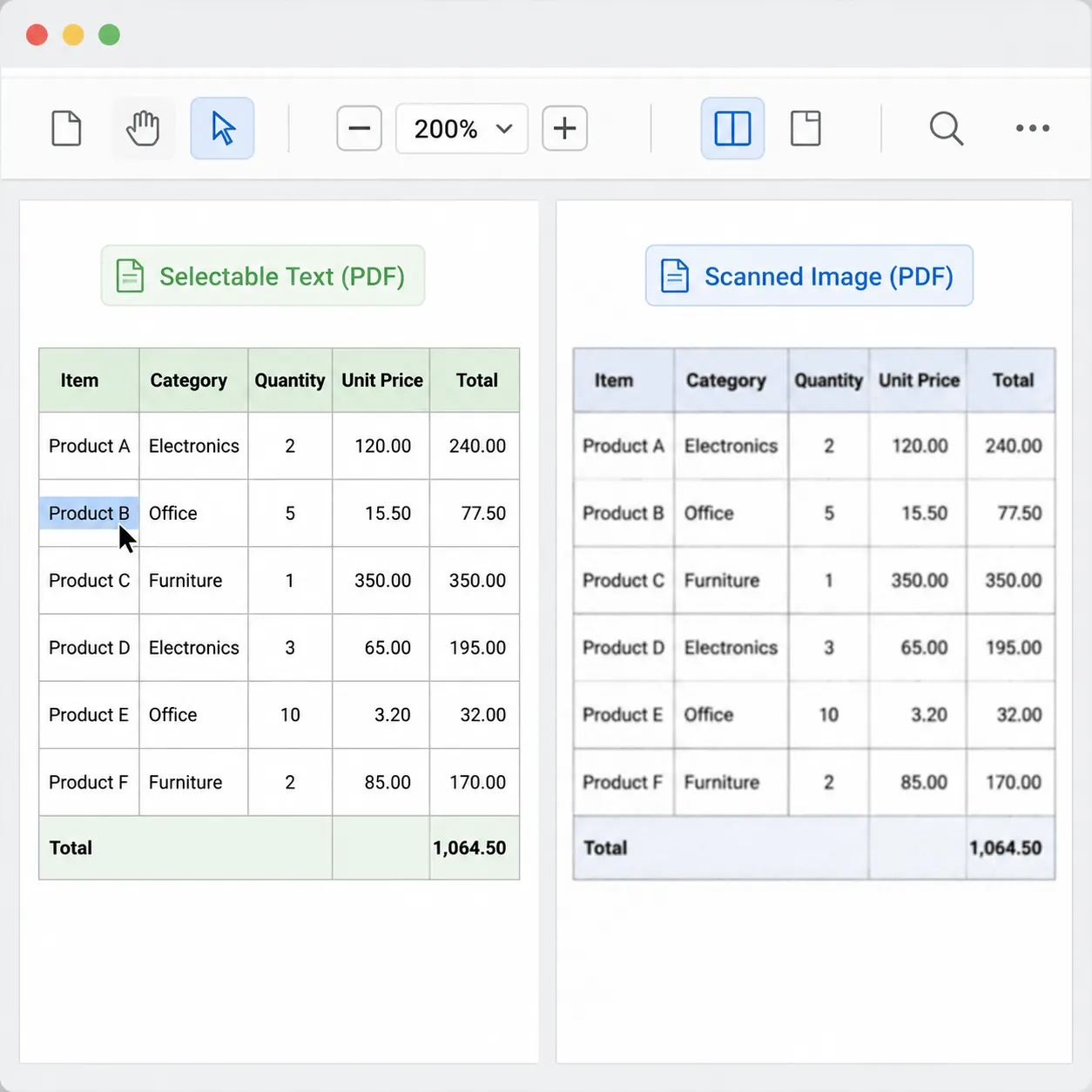
同样叫“PDF表格”,本质可能完全不同:一种是文本型PDF(里面有真实文字和表格线),另一种是扫描型PDF(其实是一张张图片)。两者的差别会直接决定你转出来是“可编辑表格”,还是“一堆识别错误”。
PDF格式转换 / 合并拆分 / 压缩加密 / OCR识别
支持电脑端 + 手机端,离线也能用
最快判断方法有3个:第一,用鼠标能否选中PDF里的文字;第二,把页面放大到200%看字边缘是否发虚;第三,复制一串数字到记事本,看是否还是数字。能选中且不发虚,基本就是文本型。
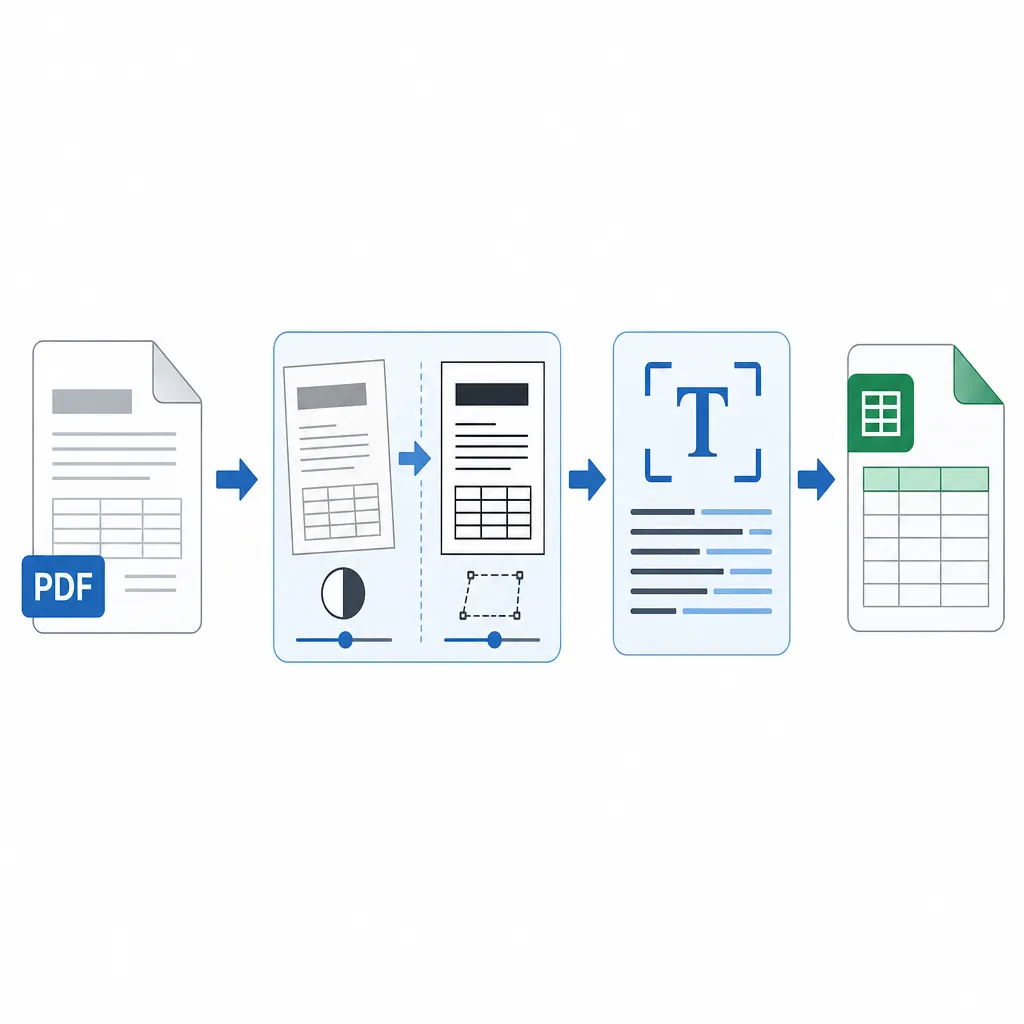
对应解决思路也很简单:文本型PDF优先直接做“PDF转Excel”;扫描型PDF要先做OCR,把图片里的字识别成文字,再导出Excel。很多人搜“pdf表格转换成excel表格”总失败,往往不是工具不行,而是文件类型选错了路径。
3种常用方法实操:从免费到省时,按场景选
方法一:用Excel自带导入/复制整理(少量、结构简单,免费)
适合:1-3页、列不多、没有复杂合并单元格的表格PDF,比如简单报价单、名单。优点是免费、上手快;缺点是遇到跨页表头、复杂排版时很容易错列。
- 打开Excel,新建空白表。
- 在PDF中框选表格区域复制(Ctrl+C)。
- 回到Excel粘贴(Ctrl+V),再用“数据”→“分列”微调。
- 用“开始”→“查找与选择”→“替换”,清理空格/换行符。
常见翻车点:粘贴后数字变成文本、同一列被拆成两列。处理技巧:选中整列→“数据”→“分列”直接点完成,或用VALUE函数把文本数字转回数值。若PDF有大量合并单元格,建议别硬扛,直接换方法二。
方法二:用pdf转excel免费转换器(批量、省事,但注意隐私)
适合:页数多、需要批量转、希望尽量保留表格结构的场景,比如每月对账单、供应商报价汇总。优点是省时间;缺点是部分免费版会限制页数/次数,且涉密文件不建议随便上传。
- 先确认PDF是文本型(能选中字符更稳)。
- 选择“PDF转Excel”功能,上传文件。
- 输出格式选 .xlsx,开始转换并下载。
- 打开Excel后,优先检查表头、金额列、小数位与合计行。
实测经验:同一份10页的采购清单,手动复制整理可能要40-60分钟;用转换器通常1-3分钟出结果,但仍要抽查关键列。遇到“列被挤在一起”,先看原PDF是否用空格对齐而非真实表格线,这类更容易错。
方法三:扫描件先OCR再导出Excel(财务报表/合同附件最常用)
适合:盖章回传的报销单、拍照的发票清单、扫描版财务报表、合同里的表格附件。优点是能处理图片型PDF;缺点是清晰度差、印章遮挡、倾斜拍摄会明显拉低准确率。
- 先检查清晰度:建议A4扫描分辨率≥300dpi,手机拍摄尽量正对、无阴影。
- 使用带OCR的工具识别文字与表格结构。
- 导出为Excel后,重点复核:金额、日期、身份证号/银行卡号等关键字段。
- 把错识别的字符统一替换(如“0/O”“1/I”“8/B”)。
小技巧:扫描件里如果表格线很淡,OCR更容易串列;可以先把PDF转成图片后做“增强对比度/去噪”,再OCR,通常能明显提升识别率。这里的核心是先让图片更像“打印件”,再谈导出。
为什么转出来总是乱?5个高频问题一次说清
问题1:表头错位、列合并混乱。多见于原PDF排版复杂、跨页表格、表头重复或有备注列。解决:先在PDF端裁剪只保留表格区域;转换后在Excel用“取消合并单元格”,再用“填充”补齐表头。

问题2:数字变文本、日期格式错乱。表现为无法求和、排序不对。解决:选中列→“数据”→“分列”→直接完成;或用=VALUE()、=DATEVALUE()批量转换。金额列建议统一设置为“数值/会计专用”。
问题3:扫描件识别错误。清晰度、字体、印章遮挡影响很大。经验值:低于200dpi的扫描件,错误率会明显上升;红色印章压在数字上,最容易把“3”识别成“8”。解决:重扫/重拍、提高对比度,必要时只对关键区域OCR。
问题4:免费版限制页数或批量次数。很多“pdf转换成excel免费版”会限制单次10页、或每天2-3次任务,批量对账时就会卡住。解决:把长PDF按页拆分后再转,或选择支持批量的工具一次性处理。
问题5:转换后还要回传或存档。财务、人事经常要把整理好的表再发回PDF。做法:在Excel里“文件”→“导出/另存为”→选择PDF,勾选“适合页面”,避免打印时被切列。这样来回流转更稳,减少二次返工。

想省时间,记住这份选择建议
最省事的决策逻辑其实很固定:少量简单表格→用Excel复制整理;页数多、结构标准→用转换器直接PDF转Excel;扫描件/拍照件→先OCR再导出。别一上来就硬转,先用“能否选中文字”把路选对。
- 看准确率:金额、日期、合计行是否稳定识别。
- 看结构保留:是否能保留列、表头与换行,而不是全挤到一列。
- 看批量能力:是否支持多文件、多页一次处理,是否有页数限制。
按岗位给个落地建议:财务优先选“OCR+复核关键字段”,因为一处金额错就要对账返工;行政、人事常见名单类PDF,文本型就直接转Excel再筛选;采购报价单若格式统一,批量转换最省时间。
总结一下:pdf转换成excel并不难,难的是没分清文本型还是扫描型,导致方法走错、结果就乱。你按本文流程先判断类型,再选对应的3种方法之一,最后用格式修正把关键列校准,基本能把返工降到最低。
如果你经常处理报表、对账单、扫描表格,建议收藏这篇,遇到文件就按步骤对照操作。需要批量把PDF稳定转成Excel、或把扫描件先OCR再导出时,可以用哔果PDF转换器作为解决方案之一:qipdf.com 。最后再提醒一次:要想pdf转换成excel少出错,先判断PDF类型再动手。