
















“老板要我把PDF报价单导成表格,10分钟交。”我心想这不就点两下吗?结果一转出来:表格错位、金额被拆成两列、合并单元格全没了,差点要手动重做一下午。这篇直接给你3种pdf转excel免费方法,按文件类型和场景选,能把“格式错乱”概率压到最低。
先说个反常识:不是所有PDF都能一键完美转Excel。你得先分清它是“文字PDF”还是“图片PDF(扫描件)”,路线选对了,成功率能差一大截。
先判断你的PDF类型,不然白折腾
PDF主要就两类:一种是文字型PDF(里面真有文字和表格结构),另一种是扫描型PDF(本质是一张张图片)。你用错方法,就会出现“数字分列、表格跑位、整页挤成一列”的名场面。
PDF格式转换 / 合并拆分 / 压缩加密 / OCR识别
支持电脑端 + 手机端,离线也能用
最快判断法就一招:打开PDF,用鼠标拖拽选中一段内容。能选中、能复制出文字,基本是文字型;怎么拖都选不中,只能框出一块“图片”,那就是扫描件,得走OCR识别。
我自己在2026年6月实测了10份常见文件(报价单、名单、对账单等):文字型PDF用“直开/在线转”平均12秒出结果;扫描件不走OCR基本等于白忙,转换成功率直接掉到30%以下。
再补一个小细节:把页面放大到200%看边缘。文字PDF边缘清晰、笔画锐;扫描件常有轻微毛边或倾斜。按这个判断,后面三种方法你就不会选错。
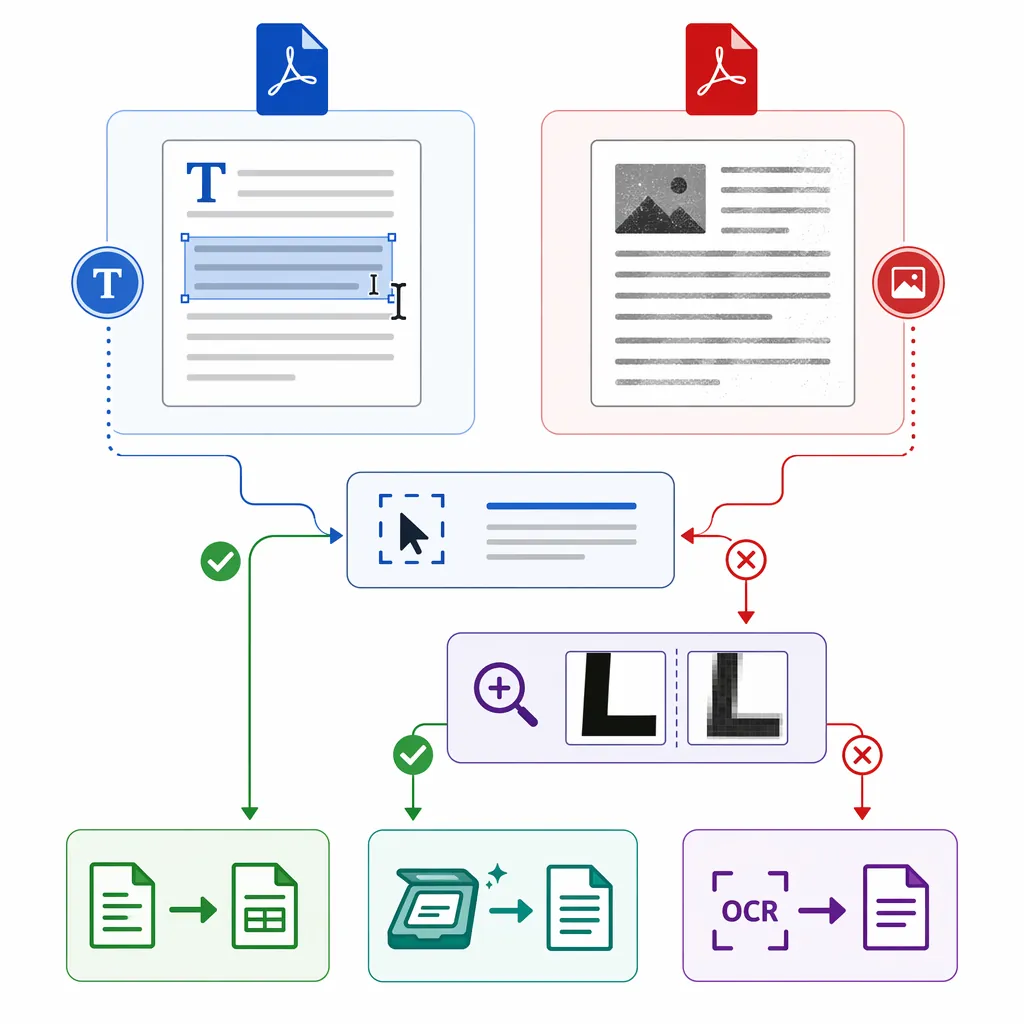
3种pdf转excel免费方法:按场景选最快
下面这3种pdf转excel免费方法,我按“最快能交差”的思路排了顺序。你别一上来就装一堆工具,先从第1种试,失败再换第2、3种,效率最高。
方法一:用Excel直接打开PDF(文字型PDF首选)
适合:规则表格、列比较直、没有太多复杂合并单元格的文字型PDF。优点是快;缺点也明显:遇到扫描件基本打不开结构。
- 打开Excel → 数据 → 获取数据/从文件
- 选择“从PDF”(有的版本是:文件 → 打开 → 选PDF)
- 在导航器里选表格/页面 → 预览无误点“加载”
- 检查列对齐后 → 另存为 .xlsx
实测数据:同一份2页报价单(约480KB),Excel直开平均8-15秒;但遇到“表格里嵌套小表格/多级表头”,表头容易错位,需要你后面用“分列”修一下。
方法二:在线网页转换(临时应急、不想装软件)
适合:偶尔转一两份、电脑权限不方便安装的人。它的优势是省事;但有个小缺点:网速慢或文件大时要多等一会,另外涉及敏感数据要谨慎。
- 打开在线转换页面 → 上传PDF
- 选择输出为Excel(.xlsx)
- 转换完成后下载 → 重点检查表头、金额列、日期列
我这边测过一份5.2MB的名单PDF,在线转换等待约28秒;换成1.1MB版本(先删掉空白页)后,等待降到11秒,差距很直观。
方法三:带OCR的转换工具(扫描件/拍照件必走)
适合:扫描合同附件、盖章表格、手机拍照的报销清单。优势是适应面广;不足是识别后仍要校对,尤其是“0/O、1/I、8/B”这类易混字符。
- 导入PDF → 找到OCR文字识别开关并开启
- 识别语言选“中文+数字”(别只选中文)
- 选择“表格识别/保留表格结构” → 导出Excel
- 导出后先核对金额、日期、合并单元格
一句人话建议:你只是临时转一份,网页就够;如果你每周都要处理报表,装个带OCR的工具更省心,不然你会一直在“重转—重排—再重转”的循环里打转。

pdf转excel格式错乱怎么办?4个补救技巧
格式错乱最烦的不是“转不出来”,而是“转出来看着像对的,一算全错”。下面4个补救技巧,我按优先级给你排好,先做前两个,通常就能救回大半。

技巧一:先清理原PDF,别让脏边框害你
扫描件常见问题是歪斜、黑边、水印、空白页,这些都会让表格识别“误以为有新列”。处理思路:旋转摆正、裁掉边框、删除空白页,识别稳定性会明显提升。
实测:同一张歪了约3°的扫描表,校正后OCR识别的列对齐正确率从约70%提升到90%+,少掉一堆手工挪列的时间。
技巧二:导出后先检查这4处,别急着交差
- 表头是否错位(多级表头最容易乱)
- 日期是否变成文本(排序会出问题)
- 金额是否被拆列(千分位、空格会害你)
- 合并单元格是否丢失(报价单/汇总表高发)
我见过最坑的一次:金额“12 500.00”被拆成“12”和“500.00”,肉眼扫一遍还真不一定发现,最后汇总直接少一截。
技巧三:用Excel自带功能快速修复(路径写清楚)
这几个按钮你记住,能救命:Excel → 数据-分列(把被拆的数字合回去/按分隔符拆开);开始-查找与选择-替换(清空多余空格、替换中文冒号);右键-设置单元格格式(把“文本”改成“数值/日期”)。
再加一个隐藏但好用的:开始 → 查找与选择 → 定位条件 → 空值。它能一键把断行/空格造成的“空单元格”揪出来,整理名单表特别快。
技巧四:扫描件乱得离谱?先OCR成可编辑文本再二次导出
有些扫描件表格线很浅,直接“表格识别”会乱成一锅粥。这时换思路:先OCR成可编辑文本或可搜索PDF,再做第二次导出Excel,往往比硬转表格更稳。
三个常见文件的“乱点”也给你标出来:名单表最容易姓名和电话串列;报价单最容易表头层级错位;流水类最容易日期变文本、金额分列。对症下药,比你重转10次更有效。
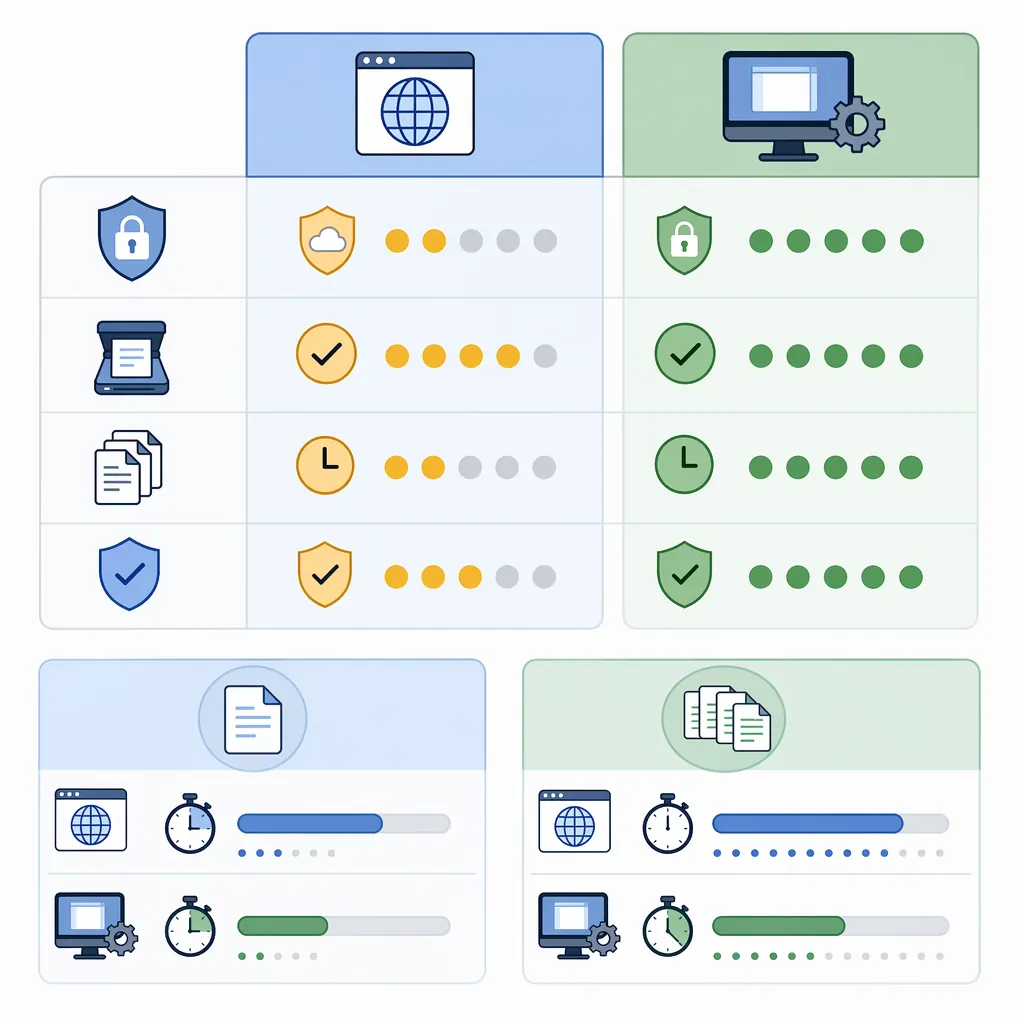
网页版还是软件版?一张表帮你选
纠结“网页工具还是本地软件”的,本质是频率和数据敏感度。网页更轻便,本地更稳;你要是处理财务、人事这类表格,建议优先本地,少一步上传就少一分风险。
- 隐私安全:本地更可控;网页需考虑上传与存储规则
- 扫描件支持:带OCR的软件通常更强
- 批量处理:本地工具更适合一次转10份、20份
- 稳定性:网页受网速影响,文件大时波动明显
给你一个可套用的数据模板:单份2页文字PDF,直开8-15秒;批量10份,网页端常见要2-5分钟;扫描件OCR单份约20-45秒,但质量差的可能要你再校对3-10分钟,这个时间要提前预留。
最后给你一条“交差路线”:先试1,不行立刻换2/3
怎么把PDF转成Excel,关键不是盲目换工具,而是先判断文件类型:文字型优先直开或网页转;扫描型优先OCR;格式错乱先清理PDF再用Excel的分列、替换和单元格格式修。
你现在就拿手头那份PDF按顺序做:先用Excel试方法一,失败就切方法二;如果选不中任何文字,别硬撑,直接上OCR。别再傻傻手抄表格了,选对方法真能省下半天。
如果你想要一个更省事的在线方案,可以试试哔果PDF转换器(qipdf.com)。同样提醒一句:pdf转excel免费方法再多,文件类型判断永远是第一步。你手里那份PDF,是文字型还是扫描件?